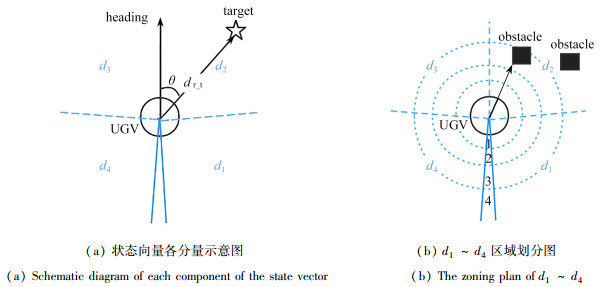
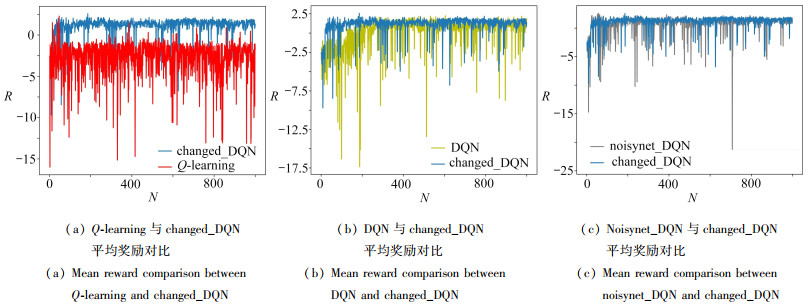
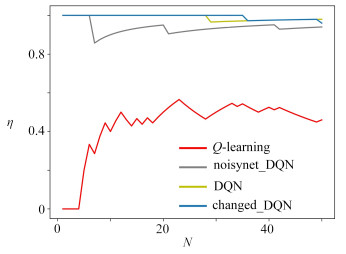
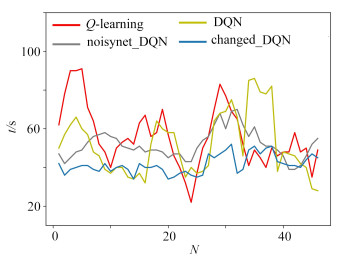
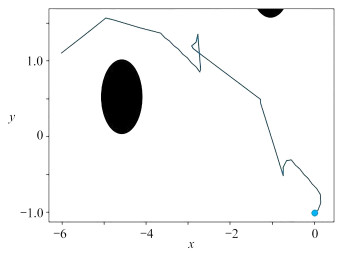
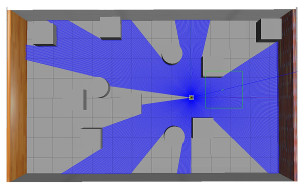
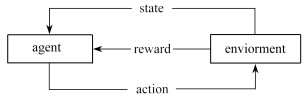
| Citation: | LI Yang, YAN Dongmei, LIU Lei. UGV Path Programming Based on the DQN With Noise in the Output Layer[J]. Applied Mathematics and Mechanics, 2023, 44(4): 450-460. doi: 10.21656/1000-0887.430070

|

| [1] |
王洪斌, 尹鹏衡, 郑维, 等. 基于改进的A*算法与动态窗口法的移动机器人路径规划[J]. 机器人, 2020, 42(3): 346-353. https://www.cnki.com.cn/Article/CJFDTOTAL-JQRR202003010.htm
WANG Hongbin, YIN Pengheng, ZHENG Wei, et al. Mobile robot path planning based on improved A* algorithm and dynamic window method[J]. Robot, 2020, 42(3): 346-353. (in Chinese) https://www.cnki.com.cn/Article/CJFDTOTAL-JQRR202003010.htm
|
| [2] |
SONG Q, LI S, ZHE L. Automatic guided vehicle path planning based on improved genetic algorithm[J]. Modular Machine Tool and Automatic Processing Technology, 2020(7): 88-92.
|
| [3] |
ZHANG S, PU J, SI Y, et al. Review on the application of ant colony algorithm in path planning of mobile robots[J]. Computer Engineering and Applications, 2020, 56(8): 10-19.
|
| [4] |
KOVÁCS B, SZAYER G, TAJTI F. A novel potential field method for path planning of mobile robots by adapting animal motion attributes[J]. Robotics and Autonomous Systems, 2016, 82: 24-34. doi: 10.1016/j.robot.2016.04.007
|
| [5] |
马丽新, 刘晨, 刘磊. 基于actor-critic算法的分数阶多自主体系统最优主-从一致性控制[J]. 应用数学和力学, 2022, 43(1): 104-114. doi: 10.21656/1000-0887.420124
MA Lixin, LIU Chen, LIU Lei. Optimal leader-following consensus control of fractional-order multi-agent systems based on the actor-critic algorithm[J]. Applied Mathematics and Mechanics, 2022, 43(1): 104-114. (in Chinese) doi: 10.21656/1000-0887.420124
|
| [6] |
刘晨, 刘磊. 基于事件触发策略的多智能体系统的最优主-从一致性分析[J]. 应用数学和力学, 2019, 40(11): 1278-1288. doi: 10.21656/1000-0887.400216
LIU Chen, LIU Lei. Optimal leader-following consensus of multi-agent systems based on event-triggered strategy[J]. Applied Mathematics and Mechanics, 2019, 40(11): 1278-1288. (in Chinese) doi: 10.21656/1000-0887.400216
|
| [7] |
CHEN Y F, LIU M, EVERETT M, et al. Decentralized non-communicating multiagent collision avoidance with deep reinforcement learning[C]//2017 IEEE International Conference on Robotics and Automation. Singapore, 2017: 285-292.
|
| [8] |
高阳, 陈世福, 陆鑫. 强化学习研究综述[J]. 自动化学报, 2004, 30(1): 86-100. https://www.cnki.com.cn/Article/CJFDTOTAL-MOTO200401010.htm
GAO Yang, CHEN Shifu, LU Xin. A review of reinforcement learning[J]. Journal of Automatica Sinica, 2004, 30(1): 86-100. (in Chinese) https://www.cnki.com.cn/Article/CJFDTOTAL-MOTO200401010.htm
|
| [9] |
YUAN X. faster finding of optimal path in robotics playground using Q-learning with "exploitation-exploration trade-off"[J]. Journal of Physics: Conference Series, 2021, 1748(2): 022008. doi: 10.1088/1742-6596/1748/2/022008
|
| [10] |
MAOUDJ A, HENTOUT A. Optimal path planning approach based on Q-learning algorithm for mobile robots[J]. Applied Soft Computing Journal, 2020, 97(A): 106796.
|
| [11] |
张宁, 李彩虹, 郭娜, 等. 基于CM-Q学习的自主移动机器人局部路径规划[J]. 山东理工大学学报(自然科学版), 2020, 34(4): 37-43. https://www.cnki.com.cn/Article/CJFDTOTAL-SDGC202004007.htm
ZHANG Ning, LI Caihong, GUO Na, et al. Local path planning of autonomous mobile robot based on CM-Q learning[J]. Journal of Shandong University of Technology (Natural Science), 2020, 34(4): 37-43. (in Chinese) https://www.cnki.com.cn/Article/CJFDTOTAL-SDGC202004007.htm
|
| [12] |
张福海, 李宁, 袁儒鹏, 等. 基于强化学习的机器人路径规划算法[J]. 华中科技大学学报(自然科学版), 2018, 46(12): 65-70. https://www.cnki.com.cn/Article/CJFDTOTAL-HZLG201812012.htm
ZHANG Fuhai, LI Ning, YUAN Rupeng, et al. Robot path planning algorithm based on reinforcement learning[J]. Journal of Huazhong University of Science and Technology (Natural Science Edition), 2018, 46(12): 65-70. (in Chinese) https://www.cnki.com.cn/Article/CJFDTOTAL-HZLG201812012.htm
|
| [13] |
王沐晨, 李立州, 张珺, 等. 基于卷积神经网络气动力降阶模型的翼型优化方法[J]. 应用数学和力学, 2022, 43(1): 77-83. doi: 10.21656/1000-0887.420137
WANG Muchen, LI Lizhou, ZHANG Jun, et al. An airfoil optimization method based on the convolutional neural network aerodynamic reduced order model[J]. Applied Mathematics and Mechanics, 2022, 43(1): 77-83. (in Chinese) doi: 10.21656/1000-0887.420137
|
| [14] |
高普阳, 赵子桐, 杨扬. 基于卷积神经网络模型数值求解双曲型偏微分方程的研究[J]. 应用数学和力学, 2021, 42(9): 932-947. doi: 10.21656/1000-0887.420050
GAO Puyang, ZHAO Zitong, YANG Yang. Study on numerical solutions to hyperbolic partial differential equations based on the convolutional neural network model[J]. Applied Mathematics and Mechanics, 2021, 42(9): 932-947. (in Chinese) doi: 10.21656/1000-0887.420050
|
| [15] |
MNIH V, KAVUKCUOGLU K, SILVER D, et al. Playing Atari with deep reinforcement learning[Z/OL]. 2013[2022-03-07].
|
| [16] |
董永峰, 杨琛, 董瑶, 等. 基于改进的DQN机器人路径规划[J]. 计算机工程与设计, 2021, 42(2): 552-558. https://www.cnki.com.cn/Article/CJFDTOTAL-SJSJ202102038.htm
DONG Yongfeng, YANG Chen, DONG Yao, et al. Robot path planning based on improved DQN[J]. Computer Engineering and Design, 2021, 42(2): 552-558. (in Chinese) https://www.cnki.com.cn/Article/CJFDTOTAL-SJSJ202102038.htm
|
| [17] |
姜兰. 基于强化学习的智能小车路径规划[D]. 硕士学位论文. 杭州: 浙江理工大学, 2019.
JIANG Lan. Intelligent car path planning based on reinforcement learning[D]. Master Thesis. Hangzhou: Zhejiang Sci-Tech University, 2019. (in Chinese)
|
| [18] |
丁志强. 基于Q学习算法的快速避障路径规划方法研究[D]. 硕士学位论文. 大连: 大连理工大学, 2021.
DING Zhiqiang. Research on fast obstacle avoidance path planning method based on Q-learning alorithm[D]. Master Thesis. Dalian: Dalian University of Technology, 2021. (in Chinese)
|
| [19] |
FORTUNATO M, AZAR M G, PIOT B, et al. Noisy networks for exploration[Z/OL]. 2018[2022-03-07].
|
| [20] |
胡刚. 基于强化学习的无地图搜索导航[D]. 硕士学位论文. 哈尔滨: 哈尔滨工业大学, 2019.
HU Gang. Mapless exploration navigation based on reinforcement learning[D]. Master Thesis. Harbin: Harbin Industrial University, 2019. (in Chinese)
|
| [21] |
王健, 赵亚川, 赵忠英, 等. 基于Q(λ)-learning的移动机器人路径规划改进探索方法[J]. 自动化与表, 2019, 34(11): 39-41. https://www.cnki.com.cn/Article/CJFDTOTAL-ZDHY201911013.htm
WANG Jian, ZHAO Yachuan, ZHAO Zhongying, et al. Improved exploration method for mobile robot path planning based on Q(λ)-learning[J]. Automation and Instrument, 2019, 34(11): 39-41. (in Chinese) https://www.cnki.com.cn/Article/CJFDTOTAL-ZDHY201911013.htm
|
| [22] |
吴夏铭. 基于深度强化学习的路径规划算法研究[D]. 硕士学位论文. 长春: 长春理工大学, 2020.
WU Xiaming. Research on path planning algorithm based on deep reinforcement learning[D]. Master Thesis. Changchun: Changchun University of Science and Technology, 2020. (in Chinese)
|
| [23] |
吴俊塔. 基于集成的多深度确定性策略梯度的无人驾驶策略研究[D]. 硕士学位论文. 深圳: 中国科学院深圳先进技术研究院, 2019.
WU Junta. Research of unmanned driving policy based on aggregated multiple deterministic policy gradient[D]. Master Thesis. Shenzhen: Shenzhen Institute of Advanced Technology, Chinese Academy of Sciences, 2019. (in Chinese)
|
| [24] |
于乃功, 王琛, 默凡凡, 等. 基于Q学习算法和遗传算法的动态环境路径规划[J]. 北京工业大学学报, 2017, 43(7): 1009-1016. https://www.cnki.com.cn/Article/CJFDTOTAL-BJGD201707006.htm
YU Naigong, WANG Chen, MO Fanfan, et al. Dynamic environment path planning based on Q-learning algorithm and genetic algorithm[J]. Journal of Beijing University of Technology, 2017, 43(7): 1009-1016. (in Chinese) https://www.cnki.com.cn/Article/CJFDTOTAL-BJGD201707006.htm
|
| [25] |
周翼, 陈渤. 一种改进dueling网络的机器人避障方法[J]. 西安电子科技大学学报, 2019, 46(1): 46-50. https://www.cnki.com.cn/Article/CJFDTOTAL-XDKD201901010.htm
ZHOU Yi, CHEN Bo. Method for obstacle avoidance based on improvement dueling Networks[J]. Journal of Xidian University, 2019, 46(1): 46-50. (in Chinese) https://www.cnki.com.cn/Article/CJFDTOTAL-XDKD201901010.htm
|
Figures(16) / Tables(3)
Supported by: Beijing Renhe Information Technology Co. Ltd




 DownLoad:
DownLoad: